Making ML-Extracted Clinical Insights Accessible
Patient Chart Extractor (PCE)
Role: Sole designer (2 engineers, 1 PM) working in close partnership with ML Platforms team
Timeline: May 2025–present (initial release Sep 2025).
Users: ~70 research oncologists and clinical analysts.
Contributions: Designed PCE, set project-agnostic development strategy, played PM-esque role in training, onboarding, and troubleshooting
Note: PCE builds on experiments detailed in "ML strategy at Flatiron."
Outcomes
PCE is a new internal app that lets non-technical users at Flatiron leverage our internal LLM platform to query batches of patient documents and extract structured insights. In practice, users can extract very accurate dates, drugs, and events from thousands of patients in 20 minutes rather than the 2 weeks it would take to do this manually.
With access to the sheer scale, processing capacity, and interpretive abilities of LLMs, Flatiron researchers can actually learn from every patient in our dataset.
PCE has unlocked $3.2 million in new revenue, solved 200+ project scoping use cases, and is now greenlit to become a data delivery vehicle by late 2026.
The Gap in Chart Review
To deliver datasets (like treatment patterns for a new drug), teams must verify its existence (can we find this drug in charts), cohort size (how many patients have taken this drug), and extraction feasibility (how many non-drug patients do we still have to look at in order to find ones that are taking it). While existing datasets cover common diseases, running bespoke models is cost-prohibitive for small-scale scoping. Internal teams required a way to ask complex questions—e.g., "How many bladder cancer patients reported nausea while on cisplatin?"—and receive verifiable counts within 30 minutes. PCE democratizes these ML-extracted insights across the organization.
Existing Workarounds
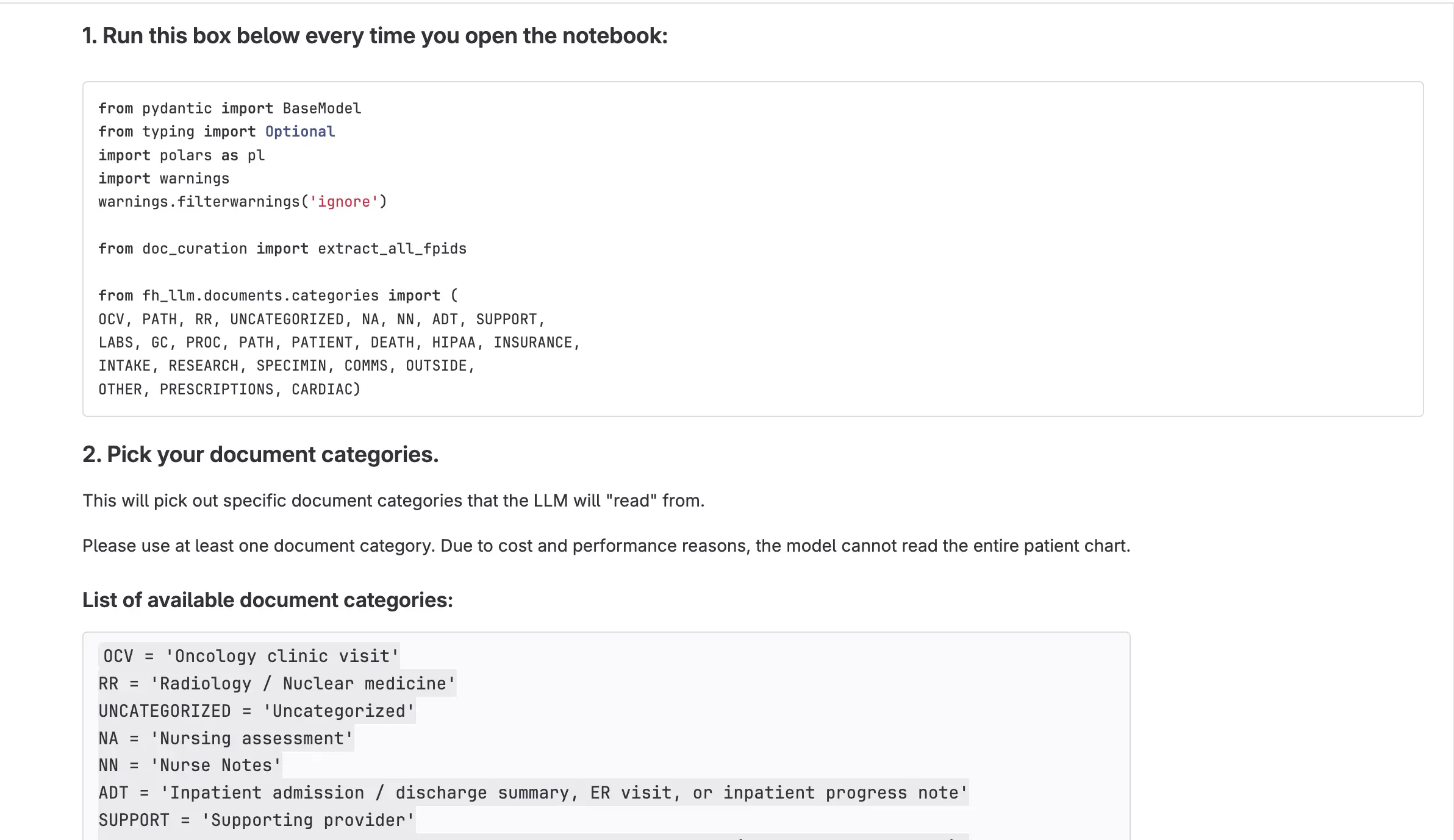
By early 2025, a few clinicians used local Jupyter notebooks our team hacked together to access fh_llm, our internal library for LLM extraction. However, maintaining local instances was unscalable and lacked visibility into user behavior. We needed a centralized web application to standardize the process.
PCE Functionality
Users create projects and build iterations by:
- Uploading a CSV of patient IDs.
- Writing a natural language extraction prompt.
- Applying document filters and keywords of interest to scope down chart content.
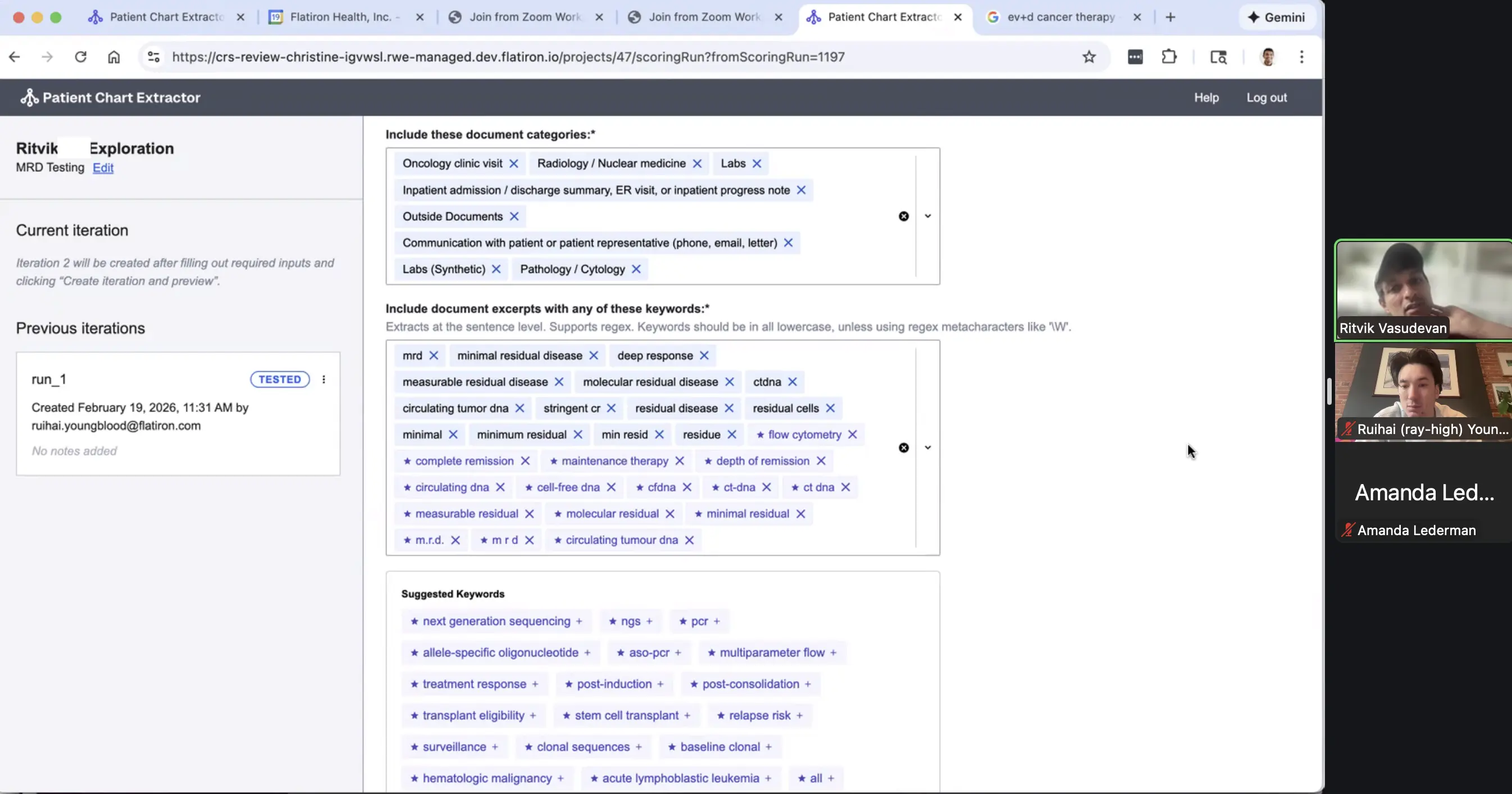
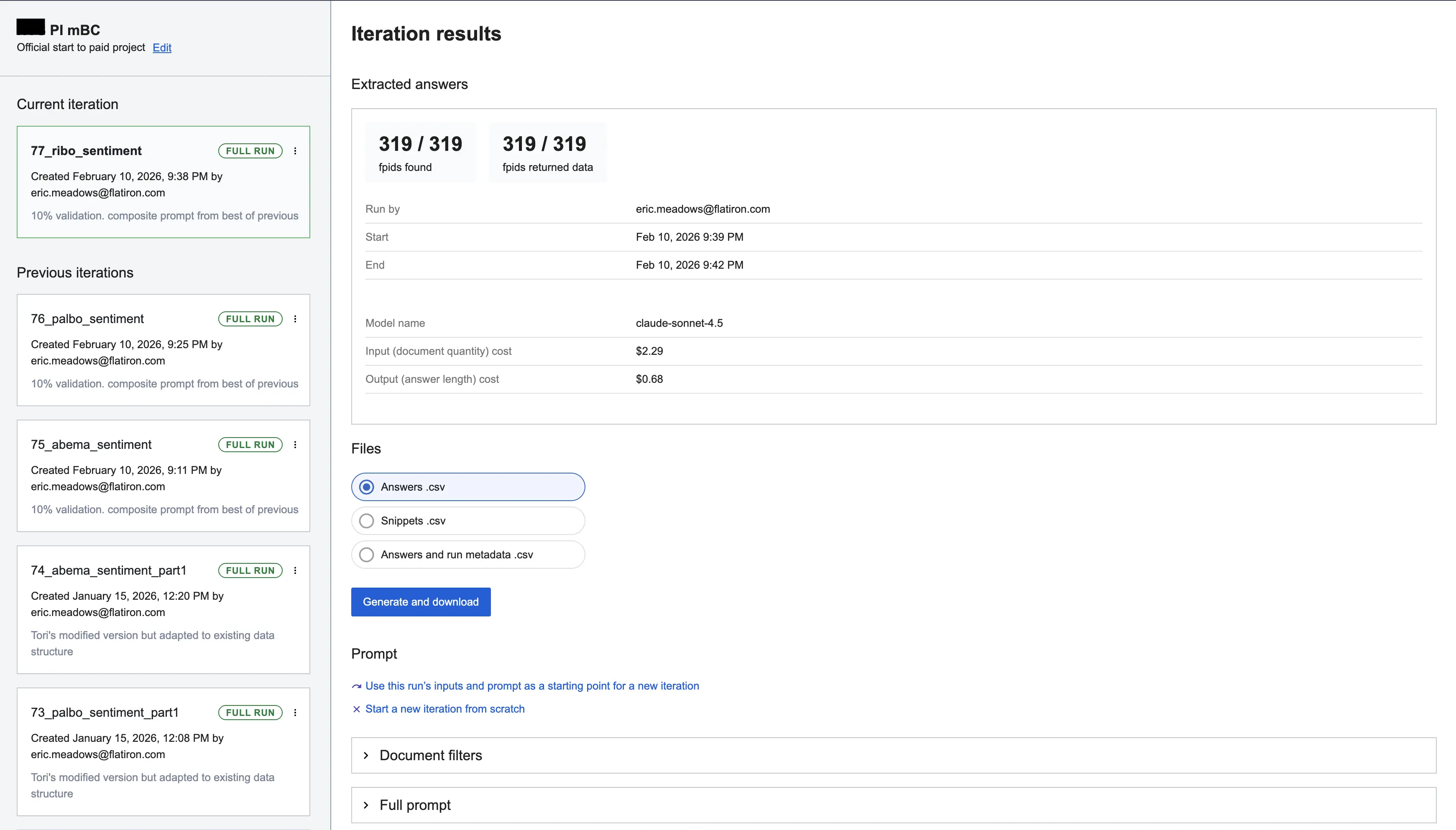
PCE provides a 3-patient preview before the full run. The system processes patients individually via Claude, validating responses against a defined schema. Users receive two CSVs: extracted data and source snippets, allowing them to verify the AI’s reasoning and refine prompts in subsequent iterations.
Core Design Decisions
1. Transparency as a Feature
I designed PCE to be "open by default." Users can view, copy, and learn from any existing work. Every action is timestamped and authored, creating an audit trail. This transformed extraction into a collaborative platform where users learn from one another’s prompt strategies.
2. Improving Design Fidelity
V1 functioned like a dense IDE on a single screen, creating high cognitive load. Feedback indicated it didn't feel like an upgrade. I pushed for V2, which delineated project stages, enabled in-app data review, and displayed performance metrics. This version made the application’s value and collaborative nature intuitive.


3. Depth Over Breadth
Users requested features for finding cohorts ("before") and data analysis ("after"). We purposefully deferred these to perfect the core extraction "slice": .csv in, .csv out. By investing in Ray LLM infrastructure, we enabled users to process 10,000 patients at once. This allowed Flatiron to pursue rare cancer projects requiring massive datasets. Focusing on this specific slice proved business value early across many project types.
Stakeholder Management
Faced with pressure to build niche features, I championed a strategy of generalized improvement based on the outcome of a Vision-setting exercise I ran. We clarified early that while the scoping team was our first partner, PCE was not a "scoping tool." By sticking to our scoped extraction slice, we built a robust tool where anyone could attempt to generate revenue or save time. This prevented the roadmap from being influenced by any single group and allowed us to discover that analytic projects—not anyone's prediction of PCE's main value—were the primary revenue drivers.

User Testing & Adoption Strategy
- Designing for Fifth Run Value over First Time Impressions: Testing for satisfaction and usability within PCE did not give us useful feedback. Our users were brand new to LLMs and did not know what was possible. While I typically adopt a "beginner mindset" during research I instead had to become a PCE expert, holding office hours and 1:1 coaching to push users to experiment. We measured our success on retention rather than ease of use, following up on PCE abandons, and noting but not prirotizing user confusion. When we saw users push PCE beyond what current abstraction capacities are (in type of data + size) we knew we had succeeded.
- Designing for Proficiency: As a result of building a tool with a high output ceiling, users went from having trouble with basic data structures to building their own advanced nested queries. I designed for optional flexibility and complexity, introducing new templates, exclusion keywords, and regex support, all of which are accessible but not necessary until a user is comfortable running PCE with baseline functionality.
- Designing Against Trust: Like all LLMs, PCE can be confidently incorrect. Initially, PCE had no mechanisms for providing feedback or improving runs, and we saw many single-iteration PCE projects with clear hallucinations. We saw this critically in keyword selection, where users would either add keywords that didn't work at all or pulled in irrelevant snippets. As a result, we built keyword suggestions (the LLM suggests how else could this data be captured in the chart), the ability to download snippets (a way to verify the source data PCE uses), and keyword statistics (what is the prevalence of keywords post-run). Now, for each feature we introduce, I consider how a user can evaluate its effect on PCE pre and post-run.
PCE Today
PCE is now greenlit to become a data delivery vehicle by late 2026.
- External Revenue: Already delivered $1.18M ($3.28M by EOQ1 '26) in new revenue within six months by enabling the analysis of lengthy physician-patient discussions at scale.
- Cost Savings: Delivered accurate counts for 150 scoping projects. In rare diseases, PCE generated $120,000 in direct and $400,000 in notional savings by standing in for manual abstraction.
- Speed to Insight: Near-zero re-extraction costs ($0.15/patient vs. $2.50 manual) allows teams to track real-world responses to new clinical data in real-time.
What I Would Do Differently
- Exit Notebooks Sooner: We over-optimized the Jupyter phase, building features that were difficult to replicate in the web app. This delayed our transition.
- Earlier IA Investment: I retained the V1 homepage too long. I should have designed for scale earlier, considering project search and group-based organization.
